
Recently I’ve had more than the average spam arriving in the inbox of my ‘throwaway’ account. It’s managing to get through the spam filters of Google, which is odd as generally I’d say they do a fair job in cleansing this sort of thing.

The first thing I noted is that it isn’t addressed to me. It’s addressed to my first name at aol.com. Apparently others have noticed this too, as I found Reddit had a few people asking questions about something very similar. Essentially we’re being bcc’d into the emails. This is one way which the sender is trying to evade rules that might prevent delivery.
Digging into the raw source reveals a lot of techniques to avoid getting trapped in the spam filter. Lets have a look at each area.
Sender Obfuscation
Received: from merchant-lan.teenycrossing.com ([109.68.190.127])
by mx.google.com with ESMTPS id 25si12470765ljo.401.2021.10.22.15.56.07
for <[email protected]>
(version=TLS1 cipher=ECDHE-ECDSA-AES128-SHA bits=128/128);
Fri, 22 Oct 2021 15:56:08 -0700 (PDT)
Received-SPF: neutral (google.com: 109.68.190.127 is neither permitted nor denied by best guess record for domain of [email protected]) client-ip=109.68.190.127;
Authentication-Results: mx.google.com;
spf=neutral (google.com: 109.68.190.127 is neither permitted nor denied by best guess record for domain of [email protected]) [email protected]
Received: from app19.muc.ec-messenger.com (app19.muc.ec-messenger.com )
(envelope-from <[email protected] ([email protected])>)
by gp13mtaq123 (mtaq-receiver/2.20190311.1) with ESMTP id yA3jJ-_S5g8Z
for <[email protected]>; Thu, 30 May 2019 19:00:22 +0200
Received: from www.takataka.gr (realshop.gr )
by uat.atnet.gr (Postfix) with ESMTPA id 24BF957C2E58
for <[email protected]>; Wed, 29 May 2019 20:27:11 +0300 (EEST)
by uat.atnet.gr (Postfix) with ESMTPA id 24BF957C2E58
Received: from mx1.banqueaudi.com (unknown ) by IMSVA (Postfix) with ESMTP id 49F9510299C; Mon,
for <[email protected]>; Wed, 29 May 2019 20:27:11 +0300 (EEST)
References: <==_mimepart_eqllB90kpiYRxTSESl_AY3hUWcJwots29J1ikvL@>
Date: Fri, 22 Oct 2021 22:51:26 UTC
List-ID: <6417211.xt.local>
CC:<[email protected]>
Content-Type: multipart/digest; boundary="==_mimepart_eqllB90kpiYRxTSESl_AY3hUWcJwots29J1ikvL"
MIME-Version: 2.0
Sender: support.QtrBJVr1Vd@
Subject: WelcomeTo Medicare 2022
From: 'Medicare Plan'<[email protected]>
Message-ID: <ZF3lf1bGTw-Ct-Y9ADdP50EpJQ2esWdHg-109.68.190.127@ismtpd0003p1iad1.sendgrid.net>You can see entries for a number of domains that this email definitely did not pass through. For starters this email was received in 2021, but there are headers here for 2019. Emails might be slow sometimes – but they don’t take over 2 years to deliver. Even the Post Office would find it difficult to take that long to deliver mail.
The Message-ID has been added to try to make filters believe that this is a ‘good’ mass mailer. The real sender is near the top: 109.68.190.127. I’m not hugely surprised to find out thats a Russian IP.
# whois.ripe.net
inetnum: 109.68.190.0 - 109.68.190.255
netname: TCTEL-190
descr: TC TEL Colocation
country: RUReply Obfuscation
Email systems are far more likely to trust a sender if an email is considered to be a reply.
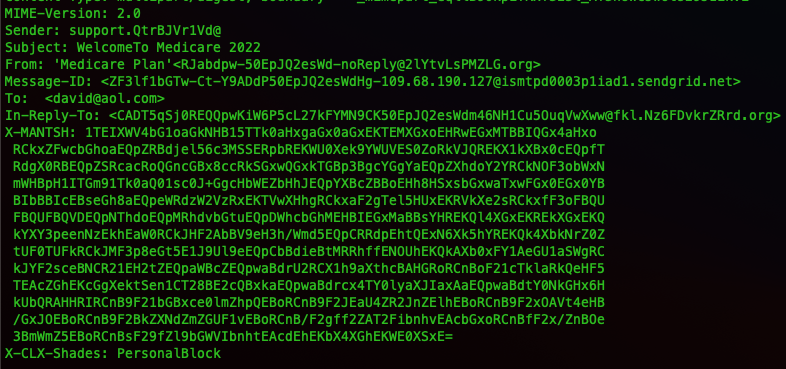
You can see here that the spam email has added an In-Reply-To header. The header X-MANTSH is not base64 encoded, it looks like gibberish but it could be something encrypted. This one would need a lot more work to see if it even is used for anything.
Body Obfuscation
When you get into the message body, things get super weird. I had to look at the RFC to even understand what was going on (specifically RFC2046).
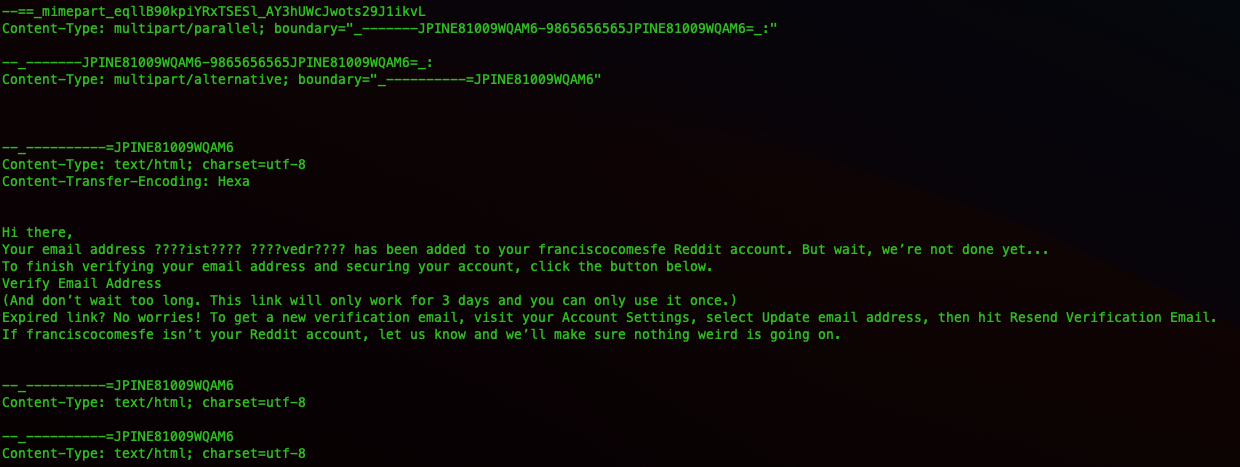
Now this text does not appear in the email as displayed. Of course it’ll be seen by an email system as it examines it for trustworthiness. Thats not the only text that doesn’t get displayed.
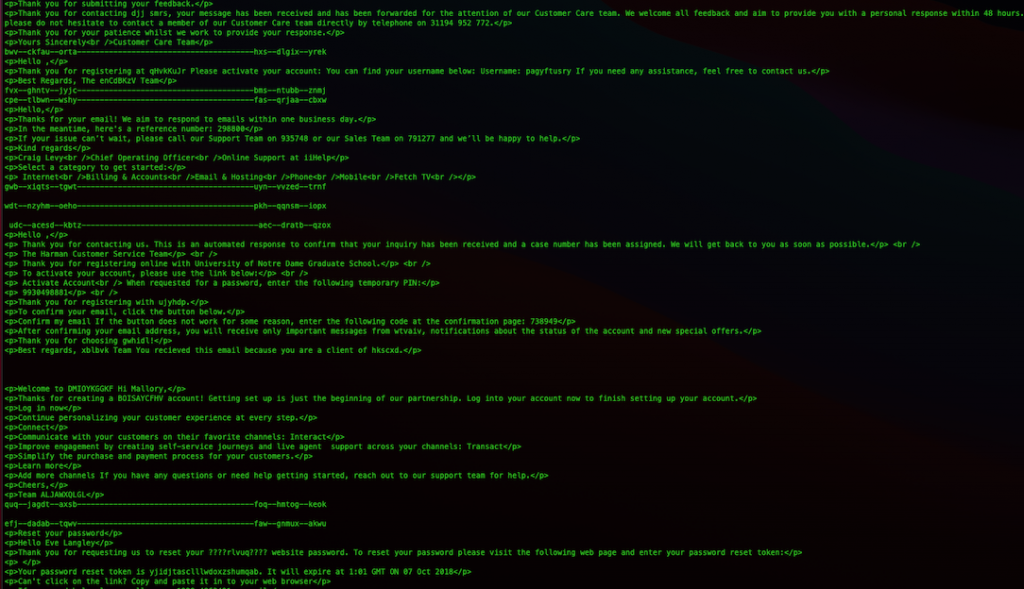
This has text from lots of different emails, and this appears below the part in the email that actually gets displayed. The code that actually is ‘run’ by our email client is here:
<CeNteR>
<a href="https://vbt5dax73pgc7xdbqq2l.s3.amazonaws.com/vbt5dax73pgc7xdbqq2l.html#qs=r-addjgaghicjgegafcfjhjgahdifehgaehjkeabababagbahcaccacjigackbfajidbcacb"><h2>2022 Medicare Open Enrollment</h2></a><br><br>
<imG SRc="https://vbt5dax73pgc7xdbqq2l.s3.amazonaws.com/vbt5dax73pgc7xdbqq2l.png" USEmAP="#">
<mAP naME="">
<aRea hReF="https://vbt5dax73pgc7xdbqq2l.s3.amazonaws.com/vbt5dax73pgc7xdbqq2l.html#qs=r-addjgaghicjgegafcfjhjgahdifehgaehjkeabababagbahcaccacjigackbfajidbcacb" coords="1,1,611,1444" shAPe="reCT">
<aRea hReF="https://vbt5dax73pgc7xdbqq2l.s3.amazonaws.com/vbt5dax73pgc7xdbqq2l.html#qs=ua-addjgaghicjgegafcfjhjgahdifehgaehjkeabababagbahcaccacjigackbfajidbcacb" coords="3,1458,612,1542" shAPe="reCT">
<aRea hReF="https://vbt5dax73pgc7xdbqq2l.s3.amazonaws.com/vbt5dax73pgc7xdbqq2l.html#qs=op-addjgaghicjgegafcfjhjgahdifehgaehjkeabababagbahcaccacjigackbfajidbcacb" coords="44,1560,544,1617" shAPe="reCT">
</MAP>
<ObJECT>
<TitLe>
<applet>You can see its been obfuscated as much as possible, yet still allows it to work. The image stored in the S3 service provided by AWS is what actually ends up being displayed. I’d imagine it’s using the free hosting tier.
So how is this actor able to have text both above and below this section and exclude it from being displayed as well as simultaneously getting the spam filters to parse it as valid?
The answer is, at least in part, MIME boundaries. In the top part of the header we see this:
Content-Type: multipart/digest; boundary="==_mimepart_eqllB90kpiYRxTSESl_AY3hUWcJwots29J1ikvL"That tells the email client it’s going to need to look for the boundary marked with what is between the quotes. Let’s refer to that as section A for simplicity. Boundaries are marked with -- before the boundary name. You can see section A being referenced here:
--==_mimepart_eqllB90kpiYRxTSESl_AY3hUWcJwots29J1ikvL
Content-Type: multipart/parallel; boundary="_-------JPINE81009WQAM6-9865656565JPINE81009WQAM6=_:"
--_-------JPINE81009WQAM6-9865656565JPINE81009WQAM6=_:
Content-Type: multipart/alternative; boundary="_----------=JPINE81009WQAM6"The top line is saying section A is made up of another section, which we’ll call B. Following this, the next line says that section B is made up of yet another section – we’ll call it C for simplicity.
It also says something important, it says section C is multipart/alternative. There are 3 entries in our raw email for section C, the first one containing gibberish, the second one containing nothing and the third one containing the actual payload. So why does the gibberish not get printed? I’ll leave that to the RFC:

Right! So now we know why the payload fires off. Immediately underneath the payload we see closing tags for sections C and B respectively.
--_----------=JPINE81009WQAM6--
--_-------JPINE81009WQAM6-9865656565JPINE81009WQAM6=_:--
--==_mimepart_eqllB90kpiYRxTSESl_AY3hUWcJwots29J1ikvL
Content-Type: text/html;
Content-Transfer-Encoding: HexaHang on, it’s opening section A with content? And it’s full of gibberish…. Why doesn’t that display? The actor can’t close off all the sections and put gibberish outside these tags as that would no doubt be detected by the spam filtering engine. The answer is actually in the payload part of section C:
<object>
<title>
<applet>Before the payload part of section C closes out it includes these three tags. By doing this the email client will not render anything below those tags. The “applet” tag is an old HTML4 tag, used back in the days of horrible shockwave plugins, and is now defunct as of HTML5.
Spamming Success
The techniques I’ve listed here are certainly contributing to both the success of bypassing filters and of avoiding ending up on spam blacklists. These emails are sailing through both Google and Apple’s spam filtering.
As I write this now, exactly zero blacklists have the actual sending domain of this email, the dubiously named teenycrossing.com, listed.
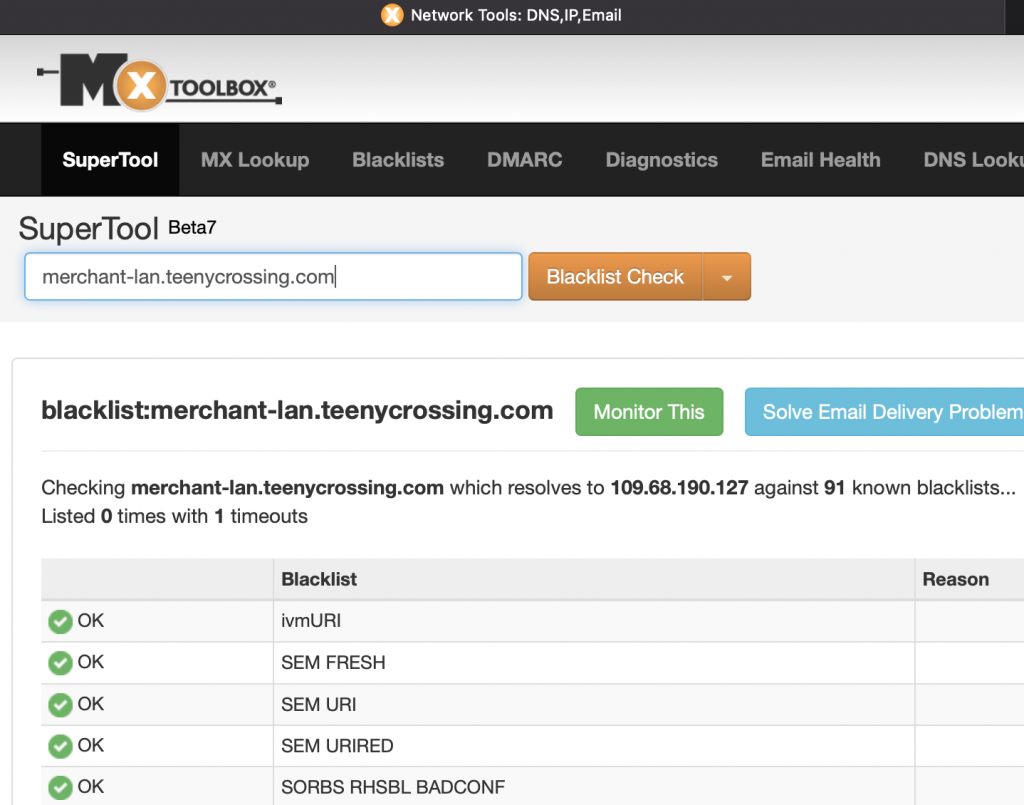
Infrastructure
Two things were not of much surprise when I started looking at the infrastructure supporting this spamming campaign. #1 is that the domain was very recently registered. #2 is seeing a hosting provider often used for nefarious activities. That could all be found out with a simple whois:
└─$ whois teenycrossing.com
Domain Name: TEENYCROSSING.COM
Registry Domain ID: 2645866657_DOMAIN_COM-VRSN
Registrar WHOIS Server: whois.namecheap.com
Registrar URL: http://www.namecheap.com
Updated Date: 2021-10-06T14:05:58Z
Creation Date: 2021-10-06T10:55:55Z
Registry Expiry Date: 2022-10-06T10:55:55Z
Registrar: NameCheap, Inc.A little dnsrecon indicates the spammer is hosting their own DNS.
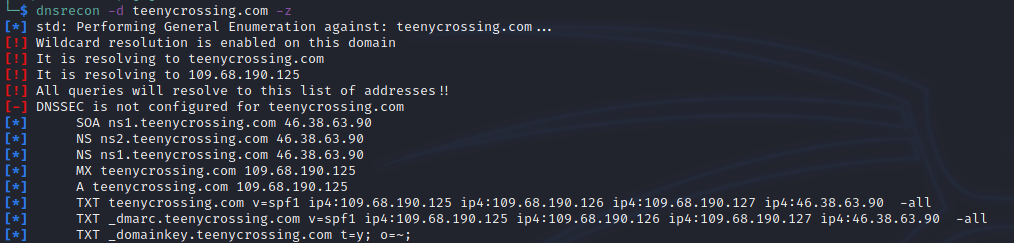
There are two NS records both pointing to 40.38.63.90. Doing a reverse lookup we find the domain art-west.ru has an A record with this IP. This domain has existed for much longer, years in fact, which is suggestive that it could be a C2 for the spam setup. There are a few reasons for a malicious actor wanting to use their own DNS infrastructure, although it’s unclear the exact purpose here.
Along with providing DNS for the spamming domain, art-west.ru also is running an email server appearing to be properly configured – I confirmed it is not an open relay.
There’s a semi-notable misconfiguration you can see in the above screenshot: the DMARC record is actually a duplicate of the SPF entry. If and when the spam domain gets blocked/taken down, it’ll be interesting to monitor in case a similar error occurs for the replacement which would point to automated deployment.
More investigation could take place into this infrastructure, but this is as far as I’ve gone – for now.
Blocking
The content within the non-displaying sections is trivial to randomise making this a difficult one for the algorithms to catch. For me, the dates in the fake headers are a giveaway and really should be enough for a heuristic filter to detect. Also I would have suspected the attempt at obfuscation of the HTML should be enough to trigger some kind of response. Apparently not…
So how do we go about blocking this? Since this is a game of cat and mouse, I don’t want to let a spammer know all of the methods that I’m using for defeating them as they’ll merely change their tactics. However, for now I can give you a rule which will prevent this specific type of spamming.
If you use Gmail, in the search box type: to:([email protected]) putting your name instead of name and then click the search options button at the end of that entry box. You can then click the ‘Create Filter’ button and get Gmail to delete emails that arrive matching this filter. You can of course create a rule doing this whatever mail provider and client you use.
Hope this is useful.
I found this post searching for info about the .xt.local sender.
This is plaguing my inbox and I am incredibly annoyed with it. Thanks for the tips to block.
Thank you for the detailed post. This is the only article I’ve found on this particular flavor of spam that is inundating my gmail inbox.
I’ve noticed that the sender is now randomizing the name in the To: addresses by appending a few random characters after my first name, which renders gmail filtering ineffective because gmail filters don’t accept wildcards.
Do you have another blocking strategy by chance? Feel free to email me if you don’t want to post publicly. I really appreciate the help!
At first glance of the Gmail filters, it’s not immediately obvious – but you can actually block the tags that the spammer is using… Specifically the HTML4 tags. For example blocking the ‘applet’ tag, which you’d never see in a genuine email, seems to prevent this particular actor quite well.